Kommunikation gilt als wichtiger Erfolgsfaktor für Softwareentwicklungsprojekte und findet in vielen Fällen mittels Sitzungen statt. Eine ungleich aufgeteilte Sprechzeit wird als Gefahrenquelle für die Effizienz von Sitzungen genannt. In diesem Projekt wurde eine Applikation entwickelt, welche die Partizipation der Teilnehmer während einer Sitzung live anzeigt und vorgängig kein sprecherspezifisches Training benötigt. Die Sprechererkennung wurde mittels Machine Learning entwickelt. Die Teilschritte Merkmalextraktion (MFCC), Segmentierung (deltaBIC-Algorithmus) und Sprecherklassifikation (I-Vectoren mit PLDA und Random Forest) wurden implementiert.
Sprechererkennung, Machine Learning, Matlab, JavaFX, Realtime, MFCC, BIC, Random Forest, I-Vector, PLDA
Das Ziel der Arbeit ist die Entwicklung einer Applikation für die Sprechererkennung während Meetings mittels Machine Learning. Die Applikation soll die Partizipation der Teilnehmer während dem Meeting live anzeigen und vorgängig kein sprecherspezifisches Training benötigen.
Kommunikation gilt als wichtiger Erfolgsfaktor für Softwareentwicklungsprojekte und findet in vielen Fällen mittels persönlicher Absprachen und Besprechungen von Entwicklergruppen statt. Es ist erwiesen, dass durch regelmässige Sitzungen und gelungener Kommunikation im Allgemeinen Mängel an Software reduziert werden können und die Wahrscheinlichkeit für den erfolgreichen Abschluss eines Softwareprojektes steigt. Trotz ihrer unbestrittenen Vorteile bergen Sitzungen auch Nachteile und können, wenn sie als ineffizient und nicht zielführend empfunden werden, negative Emotionen und folglich tiefere Produktivität auslösen. Unter anderem wird eine ungleiche Partizipation der Teilnehmer als Gefahrenquelle für die Effizienz von Sitzungen genannt.
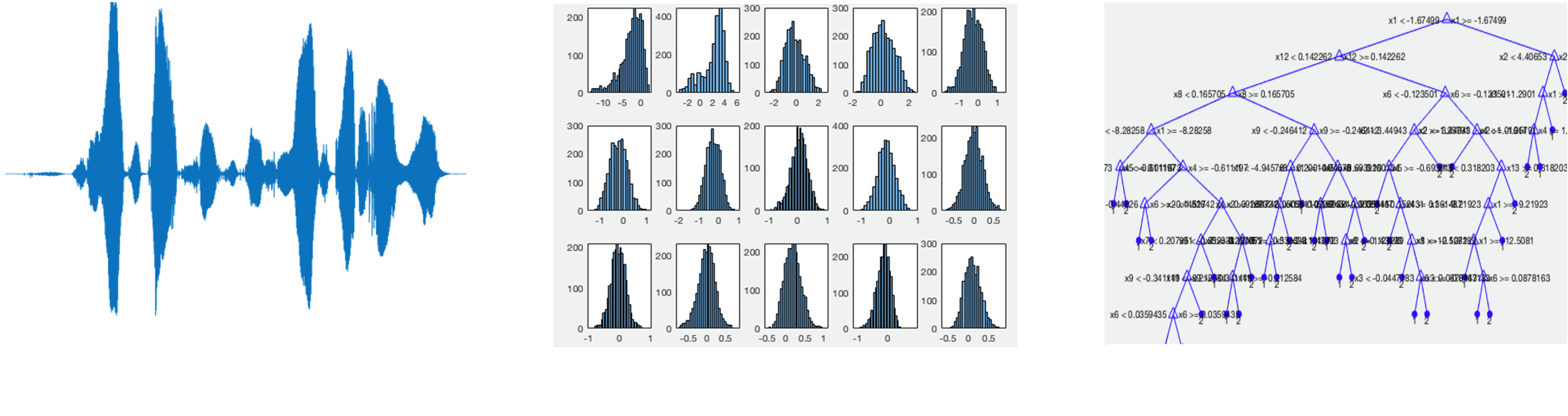
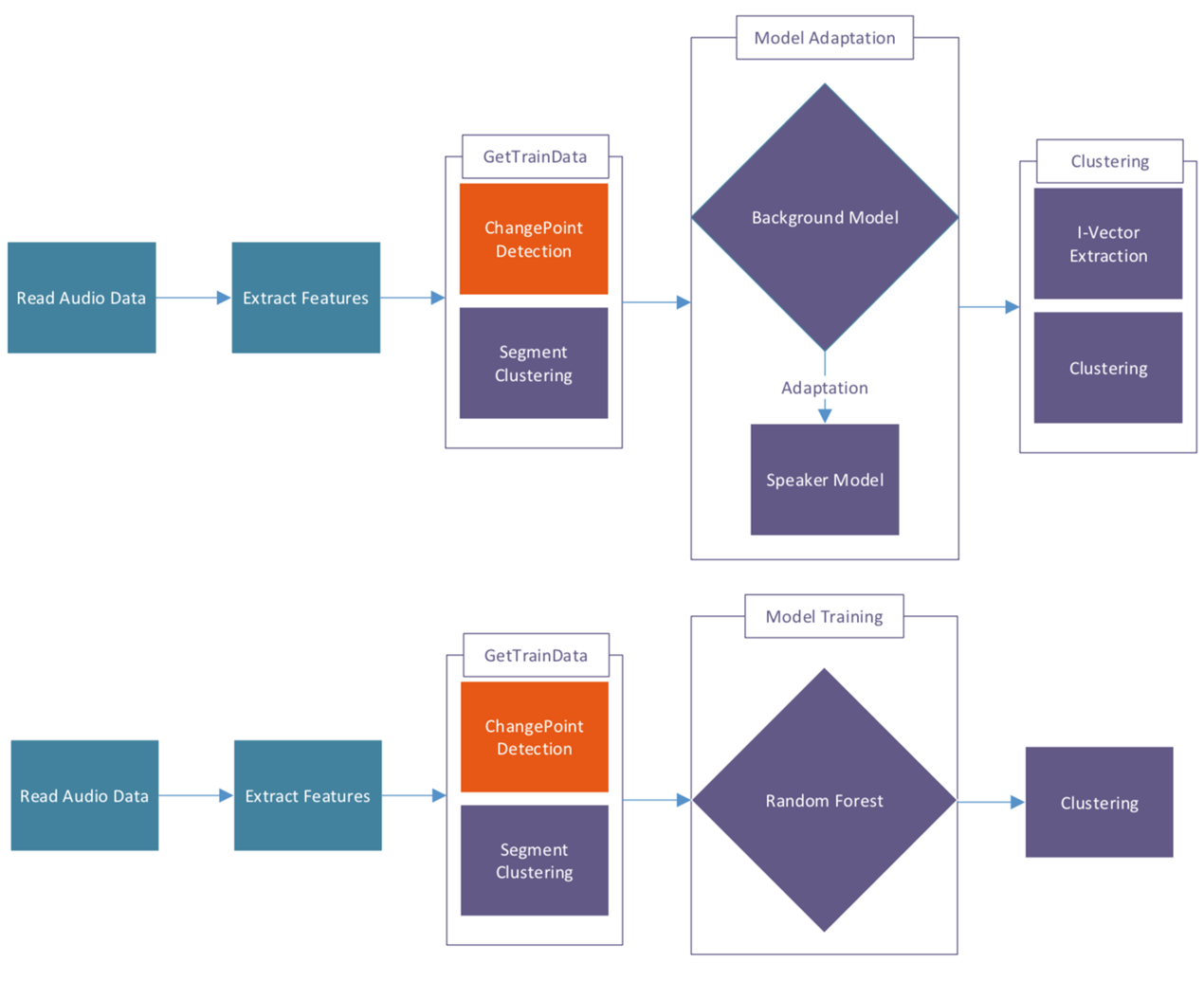
Die Sprechererkennung wurde mit Hilfe von Machine Learning Algorithmen in Matlab entwickelt. Für die Anzeige des aktuellen Sprechers, sowie der Aufteilung der Sprechzeit der jeweiligen Teilnehmer auf die Gesamtsprechzeit wurde eine GUI in Java entwickelt. Für die Sprechererkennung werden die Teilschritte Merkmalextraktion, Segmentierung und Sprecherklassifikation implementiert. Die sprecherspezifischen Merkmale werden mittels Mel-Frequency Cepstral Coefficients (MFCC) extrahiert. Bei der Segmentierung wird der kontinuierliche Audiostream in sprecherhomogene Abschnitte eingeteilt. Dazu werden zuerst die Sprecherwechsel mit dem deltaBIC-Algorithmus detektiert, um anschliessend die entstandenen Segmente mit dem gleichen Algorithmus in sprecherhomogene Gruppen einzuteilen. Diese sprecherhomogenen Gruppen dienen dann als Grundlage für das Training der Klassifikationsmodelle. Für die Sprecherklassifikation werden zwei unterschiedliche Modelle implementiert. Das erste Klassifikationsmodell gehört zur Gruppe der Background-Modelle und wurde mit I-Vektoren und Probabilistic Linear Discriminant Analysis (PLDA) umgesetzt. Das zweite Klassifikationsmodell ist der Gruppe der Majority Voting Modelle zuzuordnen und ist mittels Random Forest implementiert.
Bachelor Thesis
Dauer: Februar 2018 - August 2018
Aufwand: circa 720 Stunden
Teamgrösse: 2
Prof. Dr. Martin Melchior
Fachhochschule Nordwestschweiz FHNW
Hochschule für Technik
Bahnhofstrasse 6
CH-5210 Windisch
FHNWMonique Nussbaumer
Line Stettler
Prof. Dr. Martin Melchior, martin.melchior@fhnw.ch