Der Job-Classifier unterteilt Webseiten mittles Machine Learning in Vakanzen und Nicht-Vakanzen.
Machine learning, Python, Scikit learn, Linear Support Vector Machine, Multinomial Naive Bayes, Model Stacking, Ensemblemodell
Webseiten möglichst genau in Vakanzen und Nicht-Vakanzen zu unterteilen.
Die Firma 4U Computing hat ein Web-Crawler der Stellen-Ausschreibungen im Internet finden soll, um diese dann in geeigneter Form zu publizieren. Um dieses Vorhaben umzusetzen müssen die Vakanzen erkannt und Webseiten ohne ein solches Stellenangebot ignoriert werden.
Wir haben eine Klassifikations-Pipeline entwickelt, die die Webseiten in Vakanzen und Nicht-Vakanzen unterteilt. Die Klassifikations-Pipeline erwartet eine HTML-Webseite als Input. Die Webseite wird im Preprossing für die Klassifikation vorbereiten. Das heisst es wird versucht alle für die Klassifikation irrelevanten Daten wie zum Beispiel HTML-Tags und Strukturelemente (Navigation, Footer) zu ignorieren.
Die vorbereiteten Daten werden nun mit einem Ensemble klassifiziert. Bei einem Ensemble werden die Daten in zwei Stufen klassifiziert. In der ersten Stufe, klassifizieren verschiedene Klassifizierer die Webseiten. In der zweiten Stufe wird mit den Resultaten der ersten Stufe eine finale Klassifikation vorgenommen. Mit Hilfe eines Ensembles von verschiedenen Modellen können individuelle Schwächen einzelner Modelle ausbalanciert werden, um so bessere Resultate zu erzielen. Die detaillierte Pipeline ist in der Abbildung zu sehen.
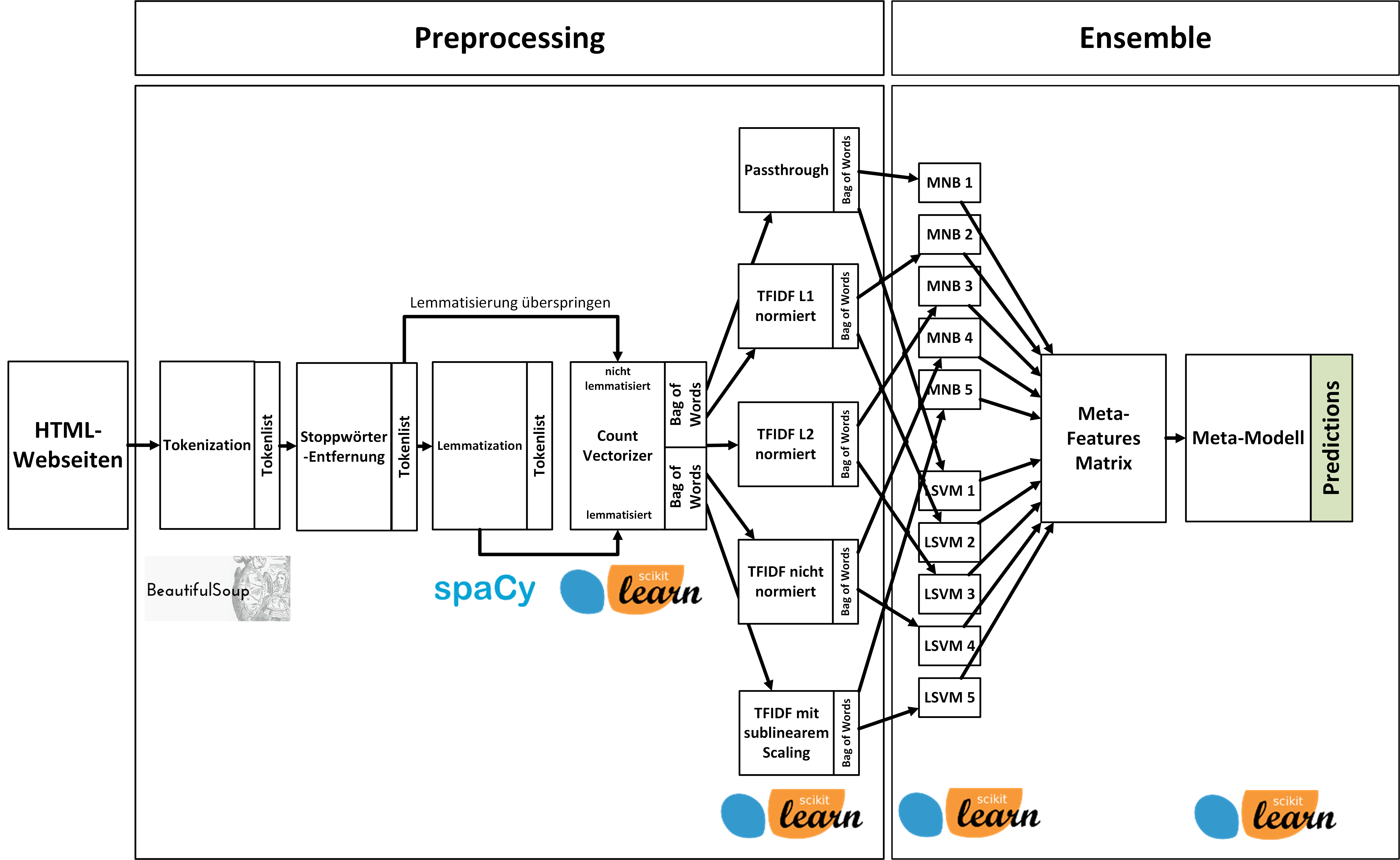
Klassifikations-Pipeline
| Projektart | Projektarbeit des 5. Semesters, IP5 |
|---|---|
| Projektdauer | 18.09.2018 - 19.01.2019 |
| Aufwand in Personenstunden | 2x 180h |
| Teamgrösse | 2 Personen |
4U Computing Badenerstrasse 13 5200 Brugg info@4u-computing.ch
Claudio Paonessa (claudio.paonessa@students.fhnw.ch)
Joel Emmenegger (joel.emmenegger@students.fhnw.ch)
Dr. Manfred Vogel (manfred.vogel@fhnw.ch)
Lukas Neukom (lukas.neukom@fhnw.ch)